D
Deleted member 1036
Guest
Background:
I normally export from SynthV using a 24-bit sample depth and a 44.1 kHz sample rate. There are two reasons for this. First, it’s good practice to work with 24-bit source files, even when the final mix will be 16-bit. Second, I’m interested in uploading to YouTube, which uses a 44.1 kHz sample rate and will resample any audio that does not conform.
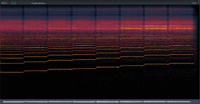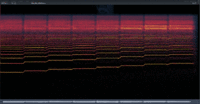
In addition to the above, I’ve often felt that SynthV voicebanks have “harsh” overtones, especially when singing higher notes. Unfortunately, this problem seems to have been carried over to Saki AI. In an attempt to solve the problem, I recently tried exporting Saki AI at 96 kHz instead of my more usual 44.1 kHz, and the result was a less harsh-sounding audio file.
As a result of my above experience, I now export at 96 kHz and then downsample to 44.1 kHz in Audacity using its highest setting.
However, I have also discovered that not only does SynthV Studio have a selectable export sample rate, it also has a selectable internal engine sample rate. This can be found by clicking on the cog wheel icon then scrolling down in the “cog” menu until the “Engine Sample Rate” option is visible.
If you try this, remember to click “Restart Live Rendering System” to implement your changes. And if the scroll bar is not visible, hover the cursor over top where you think it should be and it will appear. SynthV Studio hides scroll bars when not in use, which is why some features may evade new users.
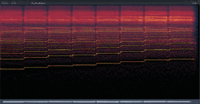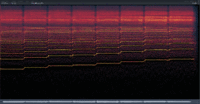
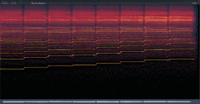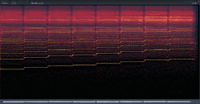
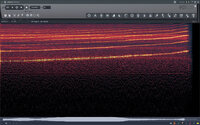
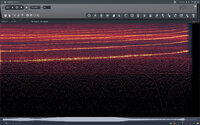
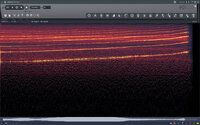
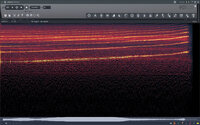
After discovering this “Engine Sample Rate” option, I decided to do some experiments. The results are as follows:
I normally export from SynthV using a 24-bit sample depth and a 44.1 kHz sample rate. There are two reasons for this. First, it’s good practice to work with 24-bit source files, even when the final mix will be 16-bit. Second, I’m interested in uploading to YouTube, which uses a 44.1 kHz sample rate and will resample any audio that does not conform.
In addition to the above, I’ve often felt that SynthV voicebanks have “harsh” overtones, especially when singing higher notes. Unfortunately, this problem seems to have been carried over to Saki AI. In an attempt to solve the problem, I recently tried exporting Saki AI at 96 kHz instead of my more usual 44.1 kHz, and the result was a less harsh-sounding audio file.
As a result of my above experience, I now export at 96 kHz and then downsample to 44.1 kHz in Audacity using its highest setting.
However, I have also discovered that not only does SynthV Studio have a selectable export sample rate, it also has a selectable internal engine sample rate. This can be found by clicking on the cog wheel icon then scrolling down in the “cog” menu until the “Engine Sample Rate” option is visible.
If you try this, remember to click “Restart Live Rendering System” to implement your changes. And if the scroll bar is not visible, hover the cursor over top where you think it should be and it will appear. SynthV Studio hides scroll bars when not in use, which is why some features may evade new users.
After discovering this “Engine Sample Rate” option, I decided to do some experiments. The results are as follows: