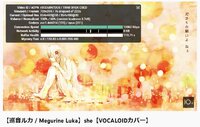
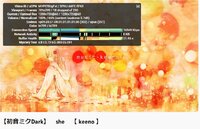
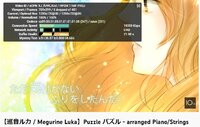
When I did my cover I processed the vocal track with: Equalizer > Digital Compressor > Tube Compressor > Analog Delay > Limiter. It took me a week to get the right plugins and tweak the settings.
The EQ was set to a "female pop vocal" preset that boosted the high-mids but had a high-high cut off at around 14k. I dropped a small, thin spike at the 1.2k mark to cut certain shrill peaks. I got interesting results if I set the gain to 'auto' but decided against it.
The digital compressor was set with an aggressive attack and release, which seemed to keep the high notes from getting too loud. One of the things that took me so long was figuring out where to set the input gain and output gain on this plugin. These settings probably had the biggest effect on the end result.
The tube compressor was fairly mild and I also used it to lower the overall volume to (I hope) match up the vocal volume with the volume of the music. I figured I should use the compressor plugin to do that, rather than just dropping the volume in the mixer. So the vocal track could be left at 0 db in the mixer. I ended up needing to set the instrumental track to -7 db but otherwise didn't alter it. This left the whole mixdown with a headroom of -2 db. I read that -2 db is ideal for uploading to Youtube and other streaming services, but I'm curious what you think.
The analog delay felt better than reverb for giving body to the vocal. I experimented between 10% and 14% wet mix and ended up around 12%. The limiter was set to -2 db and only triggered a few times throughout. I kept messing with everything until I felt the song sounded right on my good headphones, my crappy earbuds, my good speakers, and it sounded okay-ish on my cheap desktop speakers.
I'm also trying to figure out how much to adjust in the Piapro tuning and how much to leave to the EQ and compressor plugins. I can lower the volume and dynamics on problem notes in Piapro, but I don't know if that is the best way to handle it. (I really spent 10+ hours over the last month just on the line "the two of us" and the word "two" finally ended up being [ Sil T th U ] [ - u: w ] with a 3/32nd note gap between and something close to "fast 2" vibrato. Brightness up, dynamics down, and a small breathiness block under the "U." You can't even hear the "T" phoneme but it forces the "th" to be pronounced distinctly instead of being overpowered by the vowel sound. I could fill a page with all the phoneme and parameter variations I messed with. I kinda preferred [ Sil T th U ] [ - w ] with the "w" taking up half the note, but felt it still sounded a bit on the shrill side.)
Someday I'm going to do my own instrument track version in a slightly lower key and at 160 bpm instead of 180 bpm. I know I can get a more emotive performance that way.
Sorry this is a long write-up, but I want to make sure I have this stuff right before I finish my second cover. I also don't know if the single voice is sufficient or if I should have added a second vocal track to make it more substantial like the original version of the song has.
The EQ was set to a "female pop vocal" preset that boosted the high-mids but had a high-high cut off at around 14k. I dropped a small, thin spike at the 1.2k mark to cut certain shrill peaks. I got interesting results if I set the gain to 'auto' but decided against it.
The digital compressor was set with an aggressive attack and release, which seemed to keep the high notes from getting too loud. One of the things that took me so long was figuring out where to set the input gain and output gain on this plugin. These settings probably had the biggest effect on the end result.
The tube compressor was fairly mild and I also used it to lower the overall volume to (I hope) match up the vocal volume with the volume of the music. I figured I should use the compressor plugin to do that, rather than just dropping the volume in the mixer. So the vocal track could be left at 0 db in the mixer. I ended up needing to set the instrumental track to -7 db but otherwise didn't alter it. This left the whole mixdown with a headroom of -2 db. I read that -2 db is ideal for uploading to Youtube and other streaming services, but I'm curious what you think.
The analog delay felt better than reverb for giving body to the vocal. I experimented between 10% and 14% wet mix and ended up around 12%. The limiter was set to -2 db and only triggered a few times throughout. I kept messing with everything until I felt the song sounded right on my good headphones, my crappy earbuds, my good speakers, and it sounded okay-ish on my cheap desktop speakers.
I'm also trying to figure out how much to adjust in the Piapro tuning and how much to leave to the EQ and compressor plugins. I can lower the volume and dynamics on problem notes in Piapro, but I don't know if that is the best way to handle it. (I really spent 10+ hours over the last month just on the line "the two of us" and the word "two" finally ended up being [ Sil T th U ] [ - u: w ] with a 3/32nd note gap between and something close to "fast 2" vibrato. Brightness up, dynamics down, and a small breathiness block under the "U." You can't even hear the "T" phoneme but it forces the "th" to be pronounced distinctly instead of being overpowered by the vowel sound. I could fill a page with all the phoneme and parameter variations I messed with. I kinda preferred [ Sil T th U ] [ - w ] with the "w" taking up half the note, but felt it still sounded a bit on the shrill side.)
Someday I'm going to do my own instrument track version in a slightly lower key and at 160 bpm instead of 180 bpm. I know I can get a more emotive performance that way.
Sorry this is a long write-up, but I want to make sure I have this stuff right before I finish my second cover. I also don't know if the single voice is sufficient or if I should have added a second vocal track to make it more substantial like the original version of the song has.
Last edited: