DTM Station wrote an article called "Just a bit left before AI singing synthesis!? With 6 years of huge progress and becoming CeVIO Creative Studio 6. CeVIO Song & Talk Starter (Satou Sasara) is about half price until the end of February for 5,538円 ($49.96)" that I've partially translated. I only translated the stuff relevant to the "new" CeVIO and ignored stuff about current CeVIO.
Note: DTM Station is a Japanese news/educational site that talks about things like Vocaloid, DAWs, MIDI, and other audio/music-related production stuff.
How to buy CeVIO Song & Talk Starter (Satou Sasara) with the 50% discount from DTM Station:
Warning: The sale only lasts through February.
(On Amazon and Vector, the current price is 10,800円 ($97.44) right now, so this is a huge deal.)
Note: You only have to buy a starter once. Since Sasara has both a talk and song voice, it unlocks both of those portions of the software. So then you just have to buy either talk or song voices for other characters like ONE song voice or Takahashi talk voice instead of starter packs for them.
What DTM Station had to say about the "new" CeVIO:
The article talks about different vocal synths like Microsoft's Rinna, Vocaloid, and CeVIO.
Now, back to the new article...
It says that CeVIO became ver 6 in December and has been continuing to develop (now they're at ver 6.1.31 as of today with free updates as usual).
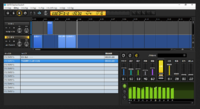
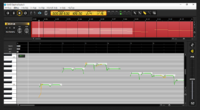
This is the demo of what Satou Sasara's voice was used for related to deep learning:
The future version of CeVIO devloped by Nagoyakogyo University and Techno-Speech, Inc. uses the HMM system (The Hidden Marvok Model) (which appears to be used by Microsoft for their speech synthesis also).
Chart DTM Station had explaining HMM in the most simple way possible that I translated:
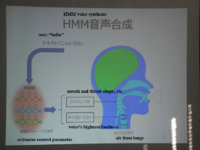
Caption on the image:
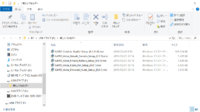
Look at them tiny file sizes. DTM Station proceeds to diss Vocaloid 5's voice bank file sizes and uses Amy as an example for being 2.2 GB, saying the difference in Vocaloid and CeVIO's software is very big (literally).
So far, CeVIO has been through 6 versions, with many (always free) updates in between to improve the software, dictionary, and voices.
Note: DTM Station is a Japanese news/educational site that talks about things like Vocaloid, DAWs, MIDI, and other audio/music-related production stuff.
How to buy CeVIO Song & Talk Starter (Satou Sasara) with the 50% discount from DTM Station:
Warning: The sale only lasts through February.
- Go to this shop (SOURCENEXT) that DTM linked to in the article.
- On the top right, click the yellow button that says カートに入れる (put in cart).
- In the クーポンを入力 (enter coupon code) spot, put in the code DTM_1902 and click 適用 (apply) so the price goes from 7,538円 ($68.01) to 5,538円 ($49.96).
(On Amazon and Vector, the current price is 10,800円 ($97.44) right now, so this is a huge deal.)
Note: You only have to buy a starter once. Since Sasara has both a talk and song voice, it unlocks both of those portions of the software. So then you just have to buy either talk or song voices for other characters like ONE song voice or Takahashi talk voice instead of starter packs for them.
What DTM Station had to say about the "new" CeVIO:
This was the article:At the end of last year, AI singing synthesis became a big topic with our article "Revolution in singing synthesis technology! Singing AI singing synthesis system sings just like a human with deep learning being developed by Nagoyakogyo University and Techno-Speech, Inc."
Links to this article: 歌声合成技術に革命!ディープラーニングで人間さながらに歌うAI歌声合成システムを名工大とテクノスピーチが開発|藤本健の “DTMステーション”"Revolution in singing voice synthesis! AI singing synthesis system sings just like a human through deep learning developed by Nagoya Institute of Technology and Techno Speech" was uploaded to DTM Station. Vocaloid has a singing ability from a different perspective, progressing to a level where it's hard to tell the difference between AI and human singing.
The article talks about different vocal synths like Microsoft's Rinna, Vocaloid, and CeVIO.
Now, back to the new article...
It says that CeVIO became ver 6 in December and has been continuing to develop (now they're at ver 6.1.31 as of today with free updates as usual).
This is the demo of what Satou Sasara's voice was used for related to deep learning:
The future version of CeVIO devloped by Nagoyakogyo University and Techno-Speech, Inc. uses the HMM system (The Hidden Marvok Model) (which appears to be used by Microsoft for their speech synthesis also).
Chart DTM Station had explaining HMM in the most simple way possible that I translated:
Caption on the image:
Singing synthesis with HMM implemented using human voice physics modeling
In other words, vocal chords vibrate with pronunciation, the throat shape and mouth openness etc. for a vocalizing human voice is calculated and the simulation is done with HMM, and a big feature of using CeVIO Creative Studio's engine is that the data usage is small.
Look at them tiny file sizes. DTM Station proceeds to diss Vocaloid 5's voice bank file sizes and uses Amy as an example for being 2.2 GB, saying the difference in Vocaloid and CeVIO's software is very big (literally).
So far, CeVIO has been through 6 versions, with many (always free) updates in between to improve the software, dictionary, and voices.
Attachments
-
 261.3 KB Views: 14
261.3 KB Views: 14
Last edited: