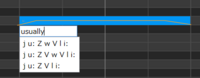
So far in all my projects I've found myself building each vocal directly from phonemes. The trouble is that we sing sounds, not words. I basically sing the line out loud and then mimic the sounds in Piapro.
For example, the dictionary has the word "face" as [ f eI s ] which makes sense. But when singing it it's too abrupt and almost just sounds like "ace." To get the what I wanted I ended up using [ f e ][ j I ][ - I s ] something like "feh'yihs" (with velocity/opening lowered on the "f"). One struggle was the word "laughs" where the dictionary's [ l0 { f s ] ends up sounding like Miku trying to say "rays" with cotton in her mouth. I finally settled on [ l0 e ](1/16th gap)[ - f s z ] with opening and velocity way low.
Then of course there's the word "the" for which I rarely seem to use [ D V ]. I've ended up using stuff like [ T e ] , [ d V ] , [ z i: ] , [ t I ] , [ D Q ] , [ th @ ] , [ dh e ] all based on context.
Some other odd words I've ended up using:
I've also found that when a voicebank sings outside their optimal range, or the note/syllable is really short it changes their pronunciation a bit. Like when I had the word "for" as a 1/16th note [ f O@ ] barely produces any kind of sound at all. I tried all kinds of things like [ f @U ][ - r ] , [ v @ r ] , [ f v Q r ] , [ v @U ][ - @U r ] , [ f Q ][ u: r ] , [ v U h r ] all with mixed results. Even adjusting the portamento alters the sound when the note is so short. I finally ended up just using [ v V ] sort of a "vuh" sound. Your brain sorta fills in the "r" sound without having to actually hear it.
One recurring high pitched syllable I struggled with was "two." If you just put [ th u: ] you just get a shrill "oo" sound and the "t" isn't really audible. I literally, actually spent at least eight hours on this one word. Every variation of phonemes, timings, vibrato, portamento, and parameters. What I finally arrived at for the line "the two of us would" was: [ d V Sil ][ T t U ](1/16th gap)[ U w ][ Sil w Q v ][ V ][ - V s ][ s w U ][ - d ] with fast, shallow vibratos, and opening low on the word "two." So like "duh - thTuh -- uw - wuv uhs swood"
One last note, I've read several places people saying that velocity and opening don't matter much. But I've found they can make a big difference. Especially on m, w, d, t, p, z, f, v. And the opening parameter affects almost every vowel sound. On one song I maxed out the opening and boosted the clearness by 20 on the whole song and it made them sound a little more like they're yelling.
I'm still getting to grips with the oddities of the Japanese phonemes. In some cases putting certain consonants together makes a unique sound. Stringing two or three vowels together with different amounts of vibrato also creates some interesting sounds. In some cases it makes a difference whether it's [ V V ] or [ V ][ V ] or [ V ][ - V ]. Then of course various uses of the [ *_0 ] devoiced sonorants both on the ends and in the middle of words causes noise most of the time, but other times gives some really interesting pronunciations. And the [ ? ] glottal stop is sorta hit-or-miss whether it does anything noticeable.
Sorry if this is a long post. I've just had a lot of this on my mind. I realize that part of this is probably me dealing with a non-native English voicebank. In the future I want to get one, maybe Avanna. Though I also want to get Elizabeth Forte at some point. I'll have to learn all the SynthV phonemes. @_@
For example, the dictionary has the word "face" as [ f eI s ] which makes sense. But when singing it it's too abrupt and almost just sounds like "ace." To get the what I wanted I ended up using [ f e ][ j I ][ - I s ] something like "feh'yihs" (with velocity/opening lowered on the "f"). One struggle was the word "laughs" where the dictionary's [ l0 { f s ] ends up sounding like Miku trying to say "rays" with cotton in her mouth. I finally settled on [ l0 e ](1/16th gap)[ - f s z ] with opening and velocity way low.
Then of course there's the word "the" for which I rarely seem to use [ D V ]. I've ended up using stuff like [ T e ] , [ d V ] , [ z i: ] , [ t I ] , [ D Q ] , [ th @ ] , [ dh e ] all based on context.
Some other odd words I've ended up using:
- "cries" = [kh @][ r Q I ][ - z z ] like "kur raheez"
- "chance" = [ Sil tS e ][ - e n z ] like "chenz"
- "me" = [ Sil m e I j ] like "meh ihy"
- "for" = [ f_0 f @U ][ - O@ ] like " hfoh wor"
- "restart" = [ r i: z ](1/16th gap)[ s t O: ][ Q@ t ] like "reez stau'hart"
- "heart" = [ h Q@ r ][ r @ t ] like "harr'rut"
- "carve" = [ kh aU ][ - r v ] like "cow wurv"
- "love" = [ l0 @ ][ V ][ - v v ] like "lar uhvv"
I've also found that when a voicebank sings outside their optimal range, or the note/syllable is really short it changes their pronunciation a bit. Like when I had the word "for" as a 1/16th note [ f O@ ] barely produces any kind of sound at all. I tried all kinds of things like [ f @U ][ - r ] , [ v @ r ] , [ f v Q r ] , [ v @U ][ - @U r ] , [ f Q ][ u: r ] , [ v U h r ] all with mixed results. Even adjusting the portamento alters the sound when the note is so short. I finally ended up just using [ v V ] sort of a "vuh" sound. Your brain sorta fills in the "r" sound without having to actually hear it.
One recurring high pitched syllable I struggled with was "two." If you just put [ th u: ] you just get a shrill "oo" sound and the "t" isn't really audible. I literally, actually spent at least eight hours on this one word. Every variation of phonemes, timings, vibrato, portamento, and parameters. What I finally arrived at for the line "the two of us would" was: [ d V Sil ][ T t U ](1/16th gap)[ U w ][ Sil w Q v ][ V ][ - V s ][ s w U ][ - d ] with fast, shallow vibratos, and opening low on the word "two." So like "duh - thTuh -- uw - wuv uhs swood"
One last note, I've read several places people saying that velocity and opening don't matter much. But I've found they can make a big difference. Especially on m, w, d, t, p, z, f, v. And the opening parameter affects almost every vowel sound. On one song I maxed out the opening and boosted the clearness by 20 on the whole song and it made them sound a little more like they're yelling.
I'm still getting to grips with the oddities of the Japanese phonemes. In some cases putting certain consonants together makes a unique sound. Stringing two or three vowels together with different amounts of vibrato also creates some interesting sounds. In some cases it makes a difference whether it's [ V V ] or [ V ][ V ] or [ V ][ - V ]. Then of course various uses of the [ *_0 ] devoiced sonorants both on the ends and in the middle of words causes noise most of the time, but other times gives some really interesting pronunciations. And the [ ? ] glottal stop is sorta hit-or-miss whether it does anything noticeable.
Sorry if this is a long post. I've just had a lot of this on my mind. I realize that part of this is probably me dealing with a non-native English voicebank. In the future I want to get one, maybe Avanna. Though I also want to get Elizabeth Forte at some point. I'll have to learn all the SynthV phonemes. @_@
Last edited: