A SIGNAL PROCESSING MOMENT?! ON MY FORUM? IT'S MORE LIKELY THAN YOU'D THINK! 
The inverse fourier transform generates the output signal in real time. Fourier transforms are basically the most common way of interacting with signals in signal processing. On the most basic level, a fourier transform converts a signal from the
time domain to the
frequency domain. It's most easy to understand by looking at a picture:
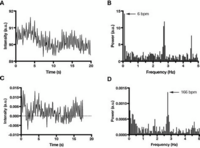
Before the fourier transform is performed, we see a constant signal being generated. But it's kind of hard to understand and modify in this form.
After we perform the fourier transform and convert the signal into the frequency domain, we see an
impulse at the frequency the signal is at. In this case, it's about ~3 hertz (Hz). Super obvious!
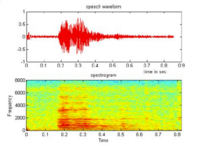
If you have an input signal that is changing frequency (pitch) over time, like a human singing voice, we can see the individual frequencies with the fourier transform!
View attachment 7276
What an artificial voice like poino does is filter a signal at a given pitch with the fourier transform to make it resemble a human voice.
For example, we can see what frequencies make up the vowel "a" like this:
View attachment 7277
Article explaining it:
Identifying sounds in spectrograms
When the spectrogram is red, there's a higher density of sound there at a certain frequency. So we want to amplify those red parts of our signal to create an "a" sound, and filter out the rest.
The fourier transform is our tool for accomplishing this. After filtering and amplifying different parts of that simple sine wave we started with, we can end up with a sound that sounds more like a human voice after inverse fourier transforming it back to the original
time domain, which you then play out of your speakers as sound.
A good article on how filtering with the inverse fourier transform works:
Intro. to Signal Processing:Fourier filter
It can be a lot to get your head around at first!
I think the more poignant difference between Adachi Rei and this software is that Missile created Rei's voice samples by hand by manually shifting the source sin wave around in Audacity and playing with every sound manually, which he then exported. On the other hand, this software is generating a voice completely algorithmically. Rei's voice is going through a lot of different layers of processing by the time you export it from UTAU, while poino generates the voice from scratch
in real time. I like Rei's voice for sitting squarely in the middle between completely algorithmically generated sound and being lovingly crafted by a person by hand.