WARNING: Twitter embeds are dumb and don't show all the pics on the preview, so make sure you click the actual tweet to see the images I reference.
Er, sorry to burst everyone's bubble, but the Cherry Pie segment was cut out of the livestream.
However, thankfully Eji went to the event and took some photos~! (Eji is someone who basically comments on every Wat tweet ever, is a big Miku fan, and goes to Crypton-related events.) (Thanks @RazzyRu for the tip.)
I'll comment on their giant tweet thread. I won't translate every word because 1) no one cares, 2) I don't have time and it's complicated and makes my brain hurt.
Tweet 1 (contains 4 pics):
I assume since this is a thread about Cherry Pie that all images are from their presentation.
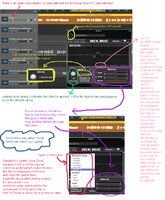
Pic 1:
It's using WaveNet, a deep neural network for generating audio. Real life examples that use WaveNet are Siri, Google Assistant, Amazon Alexa, and Cortana (so WaveNet generates speech from text for those assitants to read to us out loud.)
WaveNet can come in two forms:
1) Concatenative TTS (text to speech): Uses recorded phonemes from a voice actor, so it can sound unnatural and make modifying the voice hard.
2) Parametric TTS: Uses math to recreate sounds, the information to recreate sounds is stored in a model. The characteristics of the output voice are controlled by inputs and is created using a voice synthesizer called a vocoder.
Based on type two mentioning vocoder, it's safe to assume that Cherry Pie is Parametric TTS (see Pic 4).
It says that WaveNet can hear emotion information.
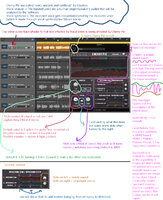
Pic 2:
The thinking bubble on the left says "It's different from my voice... I feel uncomfortable..."
The one on the right says "It's close to my voice! I don't feel uncomfortable!" (the box between him says "process").
It's too blurry and complex for me and I literally don't know the English words for this, but it's basically: There are 2 types of hearing, 1 = the oscillation heard in ear bones, 2 = the oscillation heard in the air. The one that sounds weird is not heard in the bones. A filter uses both ear and bone sounds to sound good.
Pic 3:
This pic talks about the spectral envelope. I don't know enough about it, I don't wanna learn about it, and I don't wanna write about it. :} But it's related to voice color (loudness, pitch) and the WaveNet model.
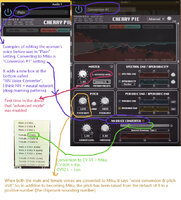
Pic 4:
Links to the Vocal Drive and Cherry Pie demo we all saw in March. It says that Cherry Pie works in real time and the words associated with it are: vocal effector, VOCODER, voice analyis synthesis, DNN voice quality conversion (DNN = deep neural network)
Tweet 2 (contains 3 pics):
Pic 1 & 2:
Explains in great detail how Vocoders/Cherry Pie works (about it being real time, about the spectral envelope, about the algorithm...). It says that the synthesis has a latency of 23-46 msec and that they have a low latency mode. This also mentions the F0, which Ryo said on Twitter that it was the most important thing in the process (you basically set the pitches arbitrarily and the F0 is where it starts and confusing crud like that, but if it's wrong, it wonks up how everything sounds).
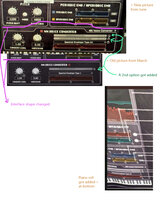
Pic 3:
This is the most interesting pic, so I'm putting it here so we can see it better:
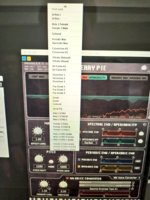
A commenter named Orahi pointed out that CV01 = Miku, CV02 R = Rin, CV02 L = Len. No sign of Luka, Meiko, or Kaito (even though nyanyannya got to use Kaito in their demo).
Another thing to note is Bel Canto #1 and #2, which is apparently Italian for "beautiful singing". Wonder what that preset does?
Lastly, it's weird that is says "Male 2 Female / Female 2 Male" instead of "Male to Female / Female to Male" (where it's "input > output" for the voices). Crypton got that rad leetspeak goin' on. So I guess "Male 2 CV01" = "Male to Miku".
I assume "Shifter+/-" moves the pitch up or down.
Er, sorry to burst everyone's bubble, but the Cherry Pie segment was cut out of the livestream.
However, thankfully Eji went to the event and took some photos~! (Eji is someone who basically comments on every Wat tweet ever, is a big Miku fan, and goes to Crypton-related events.) (Thanks @RazzyRu for the tip.)
I'll comment on their giant tweet thread. I won't translate every word because 1) no one cares, 2) I don't have time and it's complicated and makes my brain hurt.
Tweet 1 (contains 4 pics):
I assume since this is a thread about Cherry Pie that all images are from their presentation.
Pic 1:
It's using WaveNet, a deep neural network for generating audio. Real life examples that use WaveNet are Siri, Google Assistant, Amazon Alexa, and Cortana (so WaveNet generates speech from text for those assitants to read to us out loud.)
WaveNet can come in two forms:
1) Concatenative TTS (text to speech): Uses recorded phonemes from a voice actor, so it can sound unnatural and make modifying the voice hard.
2) Parametric TTS: Uses math to recreate sounds, the information to recreate sounds is stored in a model. The characteristics of the output voice are controlled by inputs and is created using a voice synthesizer called a vocoder.
Based on type two mentioning vocoder, it's safe to assume that Cherry Pie is Parametric TTS (see Pic 4).
It says that WaveNet can hear emotion information.
Pic 2:
The thinking bubble on the left says "It's different from my voice... I feel uncomfortable..."
The one on the right says "It's close to my voice! I don't feel uncomfortable!" (the box between him says "process").
It's too blurry and complex for me and I literally don't know the English words for this, but it's basically: There are 2 types of hearing, 1 = the oscillation heard in ear bones, 2 = the oscillation heard in the air. The one that sounds weird is not heard in the bones. A filter uses both ear and bone sounds to sound good.
Pic 3:
This pic talks about the spectral envelope. I don't know enough about it, I don't wanna learn about it, and I don't wanna write about it. :} But it's related to voice color (loudness, pitch) and the WaveNet model.
Pic 4:
Links to the Vocal Drive and Cherry Pie demo we all saw in March. It says that Cherry Pie works in real time and the words associated with it are: vocal effector, VOCODER, voice analyis synthesis, DNN voice quality conversion (DNN = deep neural network)
Tweet 2 (contains 3 pics):
Pic 1 & 2:
Explains in great detail how Vocoders/Cherry Pie works (about it being real time, about the spectral envelope, about the algorithm...). It says that the synthesis has a latency of 23-46 msec and that they have a low latency mode. This also mentions the F0, which Ryo said on Twitter that it was the most important thing in the process (you basically set the pitches arbitrarily and the F0 is where it starts and confusing crud like that, but if it's wrong, it wonks up how everything sounds).
Pic 3:
This is the most interesting pic, so I'm putting it here so we can see it better:
A commenter named Orahi pointed out that CV01 = Miku, CV02 R = Rin, CV02 L = Len. No sign of Luka, Meiko, or Kaito (even though nyanyannya got to use Kaito in their demo).
Another thing to note is Bel Canto #1 and #2, which is apparently Italian for "beautiful singing". Wonder what that preset does?
Lastly, it's weird that is says "Male 2 Female / Female 2 Male" instead of "Male to Female / Female to Male" (where it's "input > output" for the voices). Crypton got that rad leetspeak goin' on. So I guess "Male 2 CV01" = "Male to Miku".
I assume "Shifter+/-" moves the pitch up or down.






 I've been following and lately it's perked up my interest even more so. So, I am eager to learn more about it as time goes on. It's definitely interesting and rather fresh, I believe.
I've been following and lately it's perked up my interest even more so. So, I am eager to learn more about it as time goes on. It's definitely interesting and rather fresh, I believe.




 .
.