Wat alerts us to Crypton's Labopton BLOG being updated:
New vocal effector / Introduction to dealing with vocal synthesis
My translation of the blog post:
[start translation]
New vocal effector / Introduction to dealing with vocal synthesis
Hello, everyone, at Crypton, I am T.Ryo who is involved with vocal synthesis-related research and development.
Up until now, not very publicly showed, but at our company, we use things like vocal signal processing, deep learning , and are dealing with a new voice technological development.
Since around last year, with several research and development members, we started to make our way to a voice-related academic conference, and are checking out the latest research.
Lately, we were able to observe things like vocal synthesis that used deep learning, and reasearch of real-time conversion of voice qualities. And, so we think there are many voice analysis synthesis technology that can be used.
As a matter of fact, at even our company, we are advancing things like our own voice analysis synthesis technology, and vocal effector research and development.
So this in this post, out of the technology we developed before now, we will introduce two VST vocal effectors.
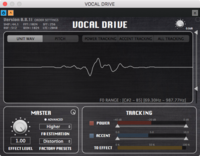
An effector called "VOCAL DRIVE" that changes the tone of voice
⦁ Simulates the phenomenon that occurs when distorting a voice, and the effector assigns a distortion effect to the voice.
⦁ Depending on the setting, effects ranging from a soft rough voice, to a pop growl, to a death growl can be produced.
 A voice analysis synthesis effector called "CHERRY PIE"
A voice analysis synthesis effector called "CHERRY PIE"
⦁ It is an effector that uses real-time high quality voice analysis synthesis technology.
⦁ Due to things like unrestricted pitch management, the spectral envelope, and modifications of indicators of non-periodic functions; the voice can be greatly altered.
⦁ Achieved through deep learning, and by reading various network files, conversion functions for voice qualities can be changed to sound like they are the voices of different people.
 Demonstration Movie
Demonstration Movie
Now, please watch the effector being practically applied in the demonstration movie.
By the way, this movie was shown to the public at ADC (Audio Developers Conference) in London on 11-20-2018. (For that reason, this is an older version than the current one.)
Translator's Note: Here is a screen shot of the settings demonstrating VOCAL DRIVE:
How was it?
We think you can understand the alteration of a voice to sound like other people with the transformation of voice qualities using the final stages of deep learning.
This is a bit technical, but in the demonstration of transforming the voice quality in the movie, both the female voice input, and male voice input, are using same conversion model (network file), so even if a female voice is inputted, or even if a male voice is inputted, we think the altered voice doesn't resemble the original one.
So we may be able to develop the technology to be like "no matter who is singing, the voice quality becomes like 〇〇"!
That was the introduction of two effectors, but we have already developed more than 10 types of effectors being used for voice production.
We are currently considering things like announcements and commercialization of the technology we have been working on. Thank you for your continued support!
[/end translation]
My thoughts:
- The voice coating seems way more natural compared to Crypton's other demos. Hopefully this is what ends up in the new Piapro.
- I think it sounds like Miku is in the demo video at 1:35? If so, her English seems to have improved a lot. (Unless editing the pitch of the singers just made the voice sound very Miku-like.)
- I think the female singer sounds like the samples that came with V5, but I checked and couldn't find any of the lines sung in the presets, so maybe I'm imagining it.
- I checked on my old translations, and around November 20th of last year, they were working on Rin and Len's "patterns" (whatever that means), and then 5 days later said they were working on Kaito. I guess it really does seem like this new tech works on both male and female voices (because the male and female singer were edited to sound identical in the demo) like Wat alluded to before.
- Hallelujah for death growl!

EDIT:
Wat retweeted this article called "Vocals of a different person with deep learning / Crypton's new technology can even be used for BABINIKU?"
Babiniku バ美肉 = Virtual (ba) bishoujo/beautiful girl (bi) incarnation (ku) バーチャル美少女受肉
Which is when a dude is a cute anime girl VTuber (even though they still have a man's voice). So the writer thinks these guys will be able to convert their voice in real time into a cute girl's. Yay! I'm excited.










 Yeah. It sounds like the thought crossed his mind, but he's deciding not to do it after all. Doesn't give me confidence when the boss man admits to wanting to jump the Vocaloid ship.
Yeah. It sounds like the thought crossed his mind, but he's deciding not to do it after all. Doesn't give me confidence when the boss man admits to wanting to jump the Vocaloid ship.







 I won't really use Death Growl alot perhaps, but pop growl yes probably.
I won't really use Death Growl alot perhaps, but pop growl yes probably.